CI/CD — Humans Need Not Apply
It’s scary how streamlined everything is nowadays. Someday, robots may even code our tests for us….

What is CI/CD?
You may have heard about CI/CD from git or other similar services that offer them. Similar terms that are also thrown around includes pipelines or script. But what is it, really?
CI/CD stands for Continuous Integration and Continuous Delivery. Both of which are different concept united under one single goal: To combine, test, and push out deliverables quickly and reliably.
Continuous Integration is the concept that tries to find a way to a consistent automated approach into checking, testing, and validating all work by the development team which can then be combined. This in turn take the burden off from the development team and drives the team to commit more small scale changes instead.
Continuous Delivery is a concept that extends Continuous Integration. Once the tested codebase is combined, Continuous Delivery will deliver the code to a selected environment of deployment. Of course, before this can take place the code must be tested first, which in turn makes sure that changes by the development team will not break the delivered product.

Why is CI/CD?
In today’s software development industry, applications can change everyday. With the rise of Agile and dynamic development with expected small but constant deliverables, developers can code new features almost everyday. Furthermore, a lot of different people could be working on the same feature at the same time. With git we can integrate these changes without worry… right?
How can we make sure that our code works well with others? Hell, how can we make sure that our code works period? That’s right, testing! Testing can be done to check if our code is working as intended and can even check if other code we just added to our codebase is working as intended.

But imagine a big application like Facebook for a second, how much time do you need to test that? Time and human resources you spend on testing are time that that developer can code new feature. But testing is indeed important. Here’s another example.
What if you feel like the features everyone have coded so far are worth pushing out to customers? What if you want to try beta testing it? Without testing, can you really be sure that your codebase is right? What if you did test, but one of your developer missed something on his routine checks? Is there any solution to this?

This is where CI/CD comes in. CI/CD automates the entire process into a streamlined reliable and fast process. You don’t need to test your program one by one by one, you can just write some tests, then write a script that automates those tests, and voila! But that’s not all. The CD part takes it further by pushing tested and verified code to the selected environment so your customers can enjoy them right away.
That may sound like a long process, yes. But see, the human intervention actually ended after the press of the enter button on the developer’s keyboard. The system then takes control, and because it’s a system, it does what it is told to do. It won’t tire out, it won’t miss a thing, and without emotion it also won’t push out stuff that have failed the tests.
How to CI/CD?
I can’t really talk about how to use CI/CD without talking about specific services. There are services like Jenkins, Travis, or Azure, but for our project, we’re using Gitlab CI that is integrated with Gitlab for ease of use and familiarity. For your own use, I suggest using one that is most familiar to you, CI/CD is there to help you, not create more problems for you.
Gitlab CI is relatively easy to use and learn. All you need to do is to add a file called .gitlab-ci.yml to your project main folder and it’ll take what you write in that file as a script. There are more advanced steps such as using a personal runner, but I’ll save that for my docker part.
Scripting Time
We’re ready to start. First, let’s get familiar with some terms. In Gitlab CI, there are pipelines, stages, and jobs.
Every time someone push a change to the codebase, Gitlab will automatically invoke a pipeline for the latest commit being pushed. A pipeline is essentially an order to running all the necessary steps on a particular piece of code.
A pipeline have stages, stages are basically separators that states what have to do be done first before the other. Say you have to compile your code first, then test it, then deploy it, then you have 3 stages.
A stage have jobs, jobs are mini tasks that can run parallel with one another, leading to a faster time. For example, if in the testing stage you have one backend test, one frontend test, and one linter test that can all run separately, you can define them as separate jobs which would run every single one right when the stage begins. Each job will be run by a runner, a sort of bot that does whatever your script says.
The usual convention for stage names are build, test, and deploy. You may use this as it is well known and understood among the community, but you may also use your own name as long as it’s not reserved. Different stages can utilize things that have been done in previous stages, and if one of the stage fails, the next stage won’t run. This is why it’s good practice to separate your deployment from your testing.
Simple Example
Let me guide you through a simple example first.
stages:
- build
- test
- deploybuild-job:
stage: build
script:
- echo "Hello $NAME"test-job1:
image: python:3.9.1
stage: test
script:
- python --versiontest-job2:
stage: test
script:
- echo "This job also tests something"
- echo "It runs the sleep command for 20 seconds"
- echo "Which simulates a 20 seconds longer test than test-job1"
- sleep 20deploy-prod:
stage: deploy
script:
- echo "This job deploys something from the commit branch."
So, what’s happening on the piece of code above? Well, first it defines all the stages in order from what have to be done first. So when the pipeline is invoked, it will in turn invoke stage build, then test, then deploy.
First of all, it runs build-job as a job in the stage build. This is where the stage-based approach came in handy. If the program was to fail being built, then it would not go to testing and deploying stage because there’s no need to. In the build job, it usually tries to build an application. Here it just prints “Hello $NAME”, but it doesn’t print $NAME…
You see, just like any scripts, we have what we variables. These variables are useful so you don’t repeatedly have to type the same things over and over and can be used to hide credentials. In Gitlab, you can enter these variables on settings > CI/CD.

Next it runs both test-job1 and test-job2 concurrently. Here test-job1 has a special attribute being it is run with an image. An image is basically an environment you want to run the commands in, here I choose python. test-job1 simply prints the current python version and exit. test-job-2 prints some string and sleep for 20 seconds. This is to simulate a longer test time, meaning when 1 is done, 2 might still be running, so deploy won’t start right away.
When both testjob-1 and 2 are done, the stage will complete and it will go to the deploy stage. Here deploy only prints, you normally would put connection to deploy your application, such as heroku among other stuff. It will deploy everything in from the branch committed to the environment. And then pipeline completes. Pretty easy, right?
Our Implementation
Then let’s take a look at our implementation. Our script is actually quite long so I’ll cut the majority of the content.




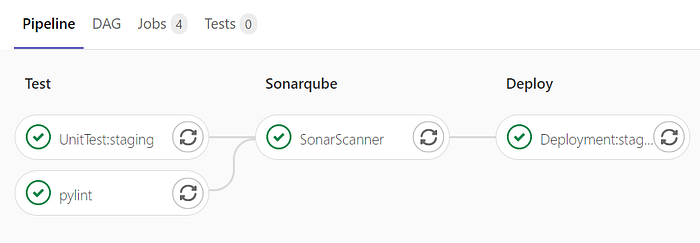
So, it may look intimidating, but let’s talk about each stage.
First we have the test stage, our application uses python so it doesn’t need any compilation. We do two things in the test stage, run unit tests and run linter.
On unit test, before_script means stuff that have to be done before the script is run, this is no different than a normal script, but this provides an extra layer of security in case something fails. On success, it will run the script and produce a coverage.xml, which we’ll use as our coverage report. Another keyword is only, meaning it will only run this script on branches with the same name, which means it’ll only run on master.
On linter, we see that it runs a few tests to see the linter score. This job actually fails if the linter score is below perfect, but there’s a new keyword, allow_failure. This will let the job count as a success while failing, meaning it can run the next stage. This is because linter doesn’t affect the “right”-ness of a code, and this further encourage faster development.

After the test is done, we do a sonarqube stage. Sonarqube runs several test such as duplications, coverage, code smell, and vulnerability. Why do we do this? Sonarqube presents us with exact numbers and locations in which we can improve the code, thus giving us verbose directions on how to improve. In this, also have the keyword except, meaning it will only run the code if the branch name does not match the one given. It won’t run on staging and master.
After the sonarqube test has passed, we finally deploy to heroku. This will push the application to heroku which will run their own tests. And after it’s done, the server will be up and running with the latest code.
Please Welcome Our Robot Overlords
CI/CD has come so far that to not use it is a real big waste, but is that all to the story though?
You see, many developers nowadays are expected to push good codes that works while being fast, but CI/CD only catch good codes after it has been pushed. Most junior developers assume that they have to test their own code in the computer first, then test it again… but that goes against the whole point of CI/CD. So how do we ensure both speed and accuracy? Well, CI/CD alone isn’t enough.
CI/CD needs to be combined with a good version control system, by providing every developer with their own playground branch, they can push codes without worrying and only merge with others when their code is clean. You see, git actually warns you to not merge when a pipeline fails. While a developer wait for a pipeline to finish, they can code, all the while they don’t have to worry about other developers as they are located in their own safe bubble.
CI/CD is an important tool, while a hammer isn’t enough to make a house by itself, it’s never wrong to have a hammer in your tool box.